
Il termine Integrazione dei Dati (o Data Integration) si riferisce al processo di unione dei dati provenienti da più fonti all’interno di un’azienda, per fornire un set di dati completo, accurato e aggiornato destinato alla BI, all’analisi dei dati e ad altre applicazioni e processi aziendali.
Include la replica, l’ingestione e la trasformazione dei dati, al fine di combinare diversi tipi di dati in formati standardizzati da archiviare in un repository di destinazione, come un Data Warehouse, un Data Lake o un Data Lakehouse.
Cinque Approcci alla Data Integration
Esistono cinque approcci principali per implementare la Data Integration: ETL, ELT, Streaming, Integrazione delle Applicazioni (API) e Virtualizzazione dei Dati. Gli ingegneri, architetti e sviluppatori di dati possono codificare manualmente l’architettura usando SQL o, più frequentemente, configurare e gestire uno strumento di Data Integration per ottimizzare e automatizzare il processo.
L’illustrazione seguente mostra dove si collocano questi approcci in un moderno processo di gestione dei dati, trasformando i dati grezzi in informazioni pulite e pronte per il business.
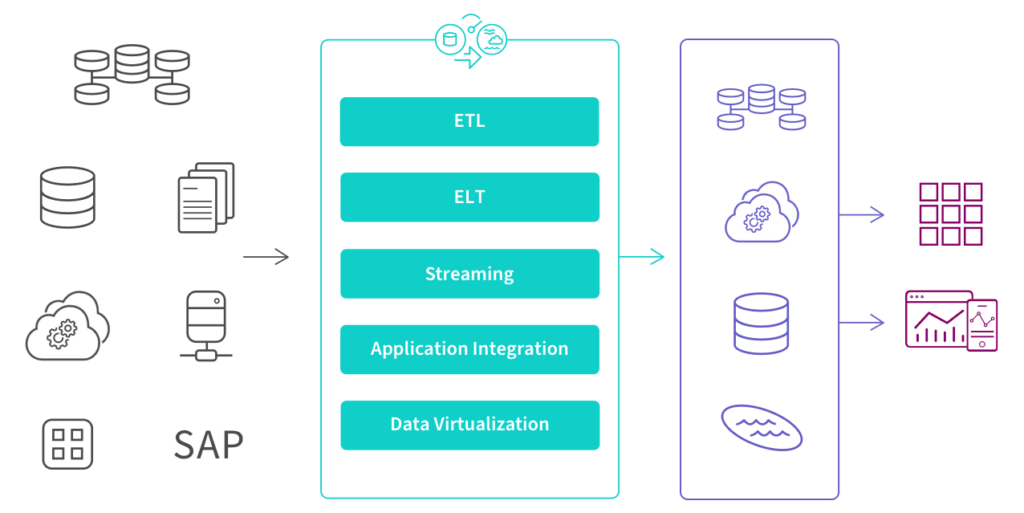
I Cinque Approcci Principali alla Data Integration
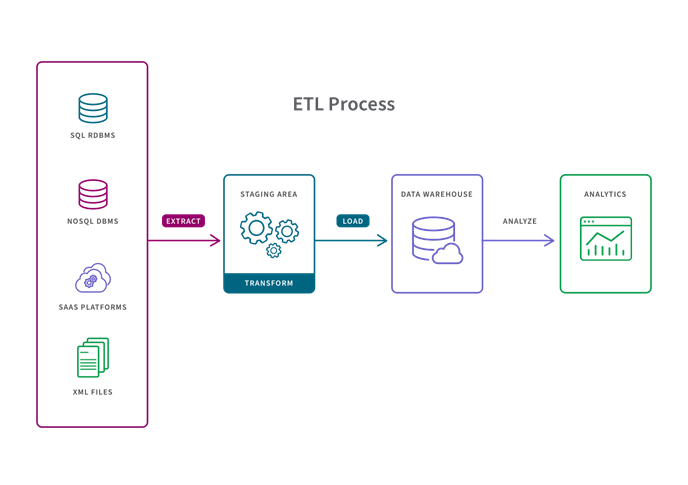
1. ETL (Extract, Transform, Load)
Una pipeline ETL è un approccio tradizionale che converte i dati grezzi tramite tre passaggi: Estrazione, Trasformazione e Caricamento. I dati vengono trasformati in un’area di staging prima di essere caricati nel repository di destinazione (generalmente un data warehouse). Questo metodo è ideale per piccoli set di dati che richiedono trasformazioni complesse.
Il Change Data Capture (CDC) è un metodo ETL che identifica e acquisisce le modifiche apportate a un database. Queste modifiche possono poi essere replicate in un altro repository o rese disponibili per strumenti di ETL, EAI o altre soluzioni di Data Integration.
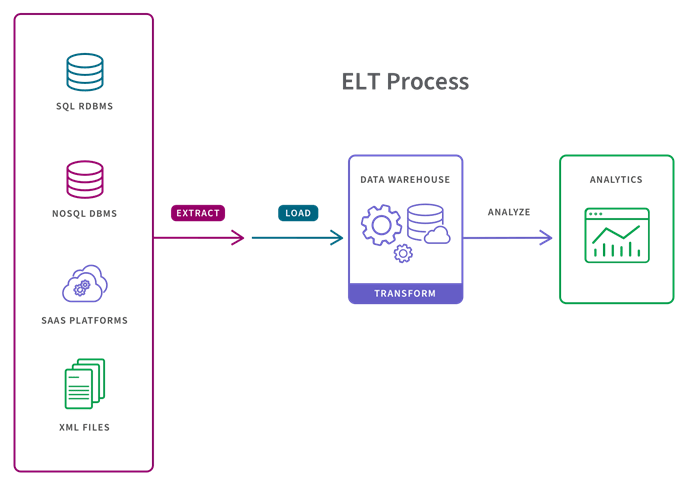
2. ELT (Extract, Load, Transform)
Nella più moderna pipeline ELT, i dati vengono caricati immediatamente e poi trasformati all’interno del sistema di destinazione, tipicamente un data lake, un data warehouse o un data lakehouse basato su cloud. Questo approccio è più adatto quando i set di dati sono di grandi dimensioni e la tempestività è importante, poiché il caricamento è spesso più veloce. L’ELT opera su scala micro-batch o CDC (Change Data Capture). Il micro-batch, o delta load, carica solo i dati modificati dall’ultimo caricamento riuscito. Il CDC, invece, carica continuamente i dati man mano che vengono modificati nella sorgente.
3. Data Streaming
Invece di caricare i dati in un nuovo repository a lotti, l’integrazione dei dati in streaming sposta i dati continuamente e in tempo reale dalla sorgente alla destinazione. Le moderne piattaforme di Data Integration (DI) possono fornire dati pronti per l’analisi su piattaforme di streaming, cloud, data warehouse e data lake.
4. Application Integration (API)
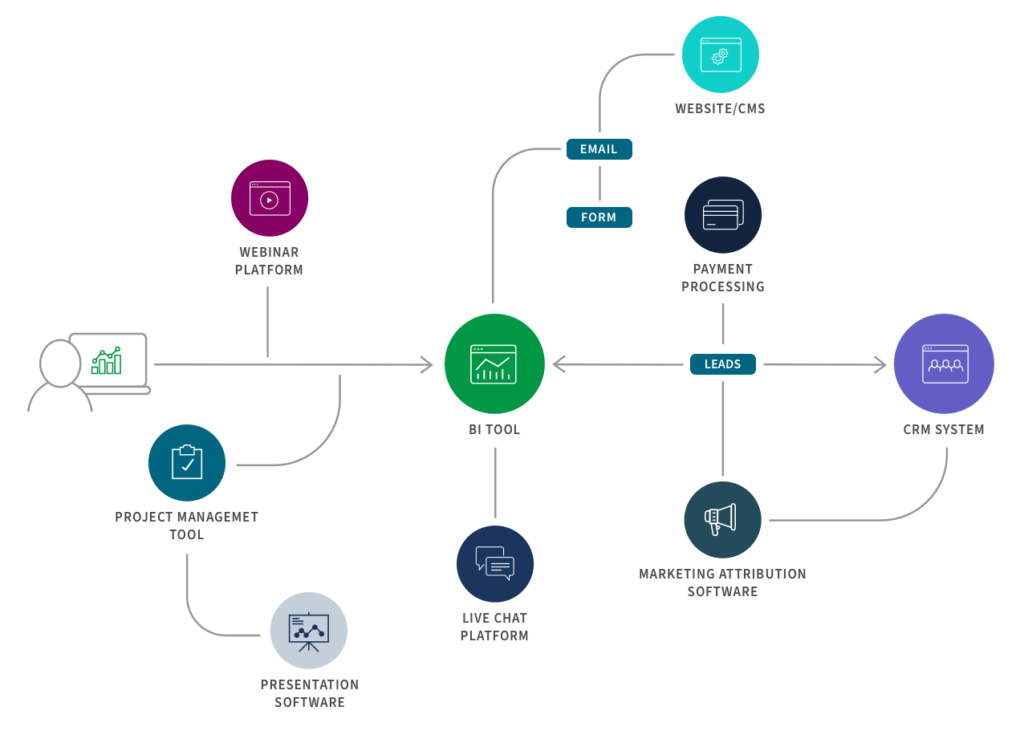
L’integrazione delle applicazioni (API) consente a diverse applicazioni di lavorare insieme spostando e sincronizzando i dati tra di loro. Il caso d’uso più tipico è il supporto delle esigenze operative, come garantire che il tuo sistema HR abbia gli stessi dati del tuo sistema finanziario. Pertanto, l’integrazione delle applicazioni deve assicurare la coerenza tra i set di dati. Inoltre, queste applicazioni hanno solitamente API uniche per inviare e ricevere dati, quindi gli strumenti di automazione delle applicazioni SaaS possono aiutarti a creare e mantenere integrazioni API native in modo efficiente e su larga scala.
Ecco un esempio di flusso di integrazione per il marketing B2B:
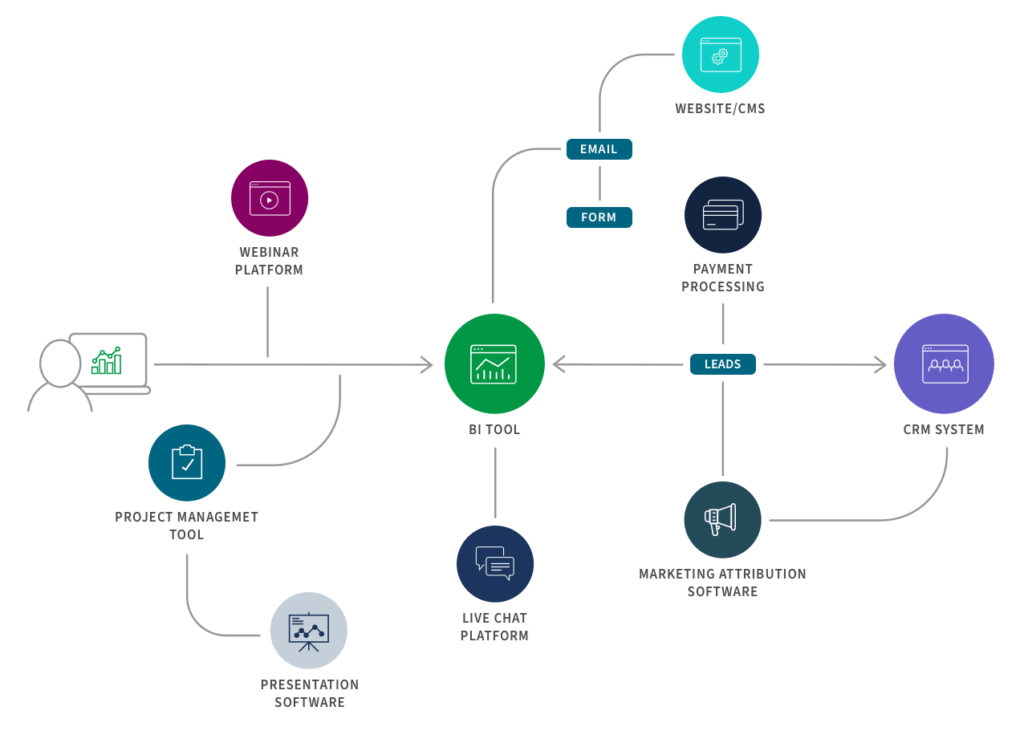
5. Data Virtualization
Come lo streaming, la virtualizzazione dei dati fornisce dati in tempo reale, ma solo quando richiesti da un utente o da un’applicazione. Tuttavia, questa tecnologia può creare una vista unificata dei dati, rendendoli disponibili su richiesta combinando virtualmente dati provenienti da diversi sistemi. La virtualizzazione e lo streaming sono particolarmente adatti per sistemi transazionali progettati per query ad alte prestazioni.
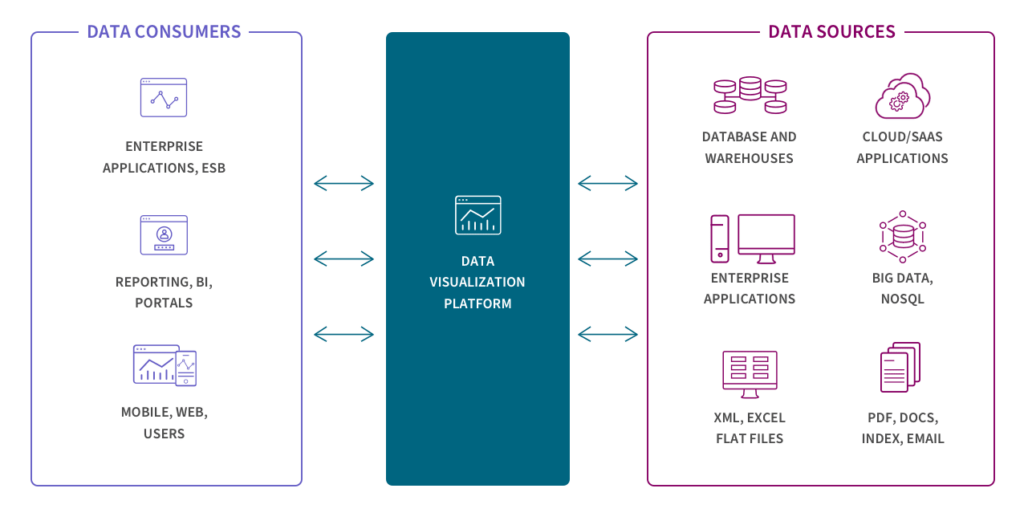
Evoluzione Continua
Ognuno di questi cinque approcci continua ad evolversi insieme all’ecosistema del Modern Data Stack. Storicamente, i data warehouse erano i repository di destinazione e, pertanto, i dati dovevano essere trasformati prima del caricamento. Questo rappresenta la pipeline ETL classica (Extract > Transform > Load), ancora appropriata per piccoli set di dati che richiedono trasformazioni complesse.
Tuttavia, con l’ascesa delle soluzioni Integration Platform as a Service (iPaaS), l’aumento dei volumi di dati, l’architettura Data Fabric e Data Mesh, e la necessità di supportare progetti di analisi in tempo reale e di Machine Learning, l’integrazione sta passando dall’approccio ETL a ELT, streaming e API.
4 Casi d’Uso principali di Data Integration
Qui ci concentreremo sui quattro principali casi d’uso: ingestione dei dati (Data Ingestion), replica dei dati (Data Replication), automazione dei Data Warehouse (Data Warehouse Automation) e integrazione dei Big Data (Big Data Integration).
Caso d’Uso #1: Data Ingestion
Il processo di Data Ingestion consiste nel trasferire i dati da una varietà di fonti a una posizione di archiviazione come un Data Warehouse o unData Lake. L’ingestione può avvenire in tempo reale o a lotti e include tipicamente la pulizia e la standardizzazione dei dati per renderli pronti per uno strumento di analisi dei dati.
Esempi di ingestione dei dati includono:
- La migrazione dei dati al cloud.
- La creazione di un data warehouse, data lake o data lakehouse.
Questo diagramma mostra come i data lake gestiti automatizzano il processo di fornitura di set di dati aggiornati, accurati e affidabili per l’analisi aziendale.
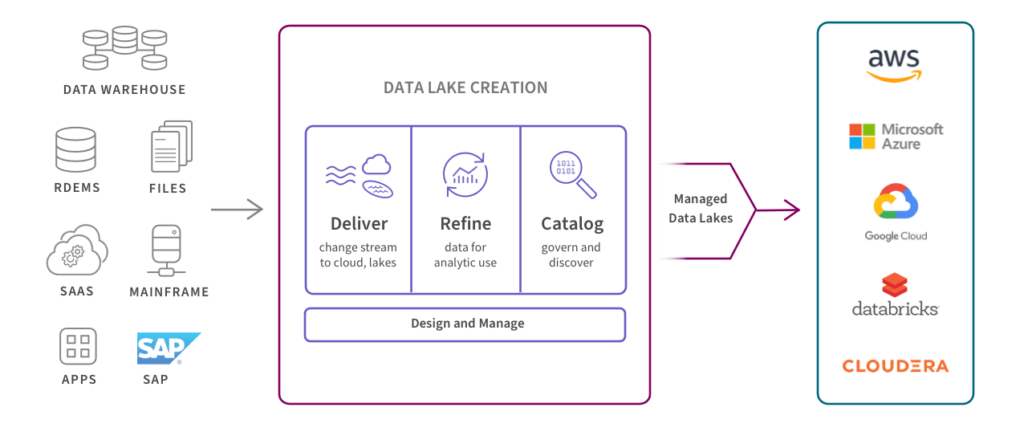
Caso d’Uso #2: Data Replication
Nel processo di replica dei dati, i dati vengono copiati e trasferiti da un sistema a un altro — ad esempio, da un database in un data center a un data warehouse nel cloud. Questo assicura che le informazioni corrette siano backup e sincronizzate per gli utilizzi operativi. La replica può avvenire:
- In blocco
- A lotti su base programmata
- In tempo reale tra data center e/o il cloud
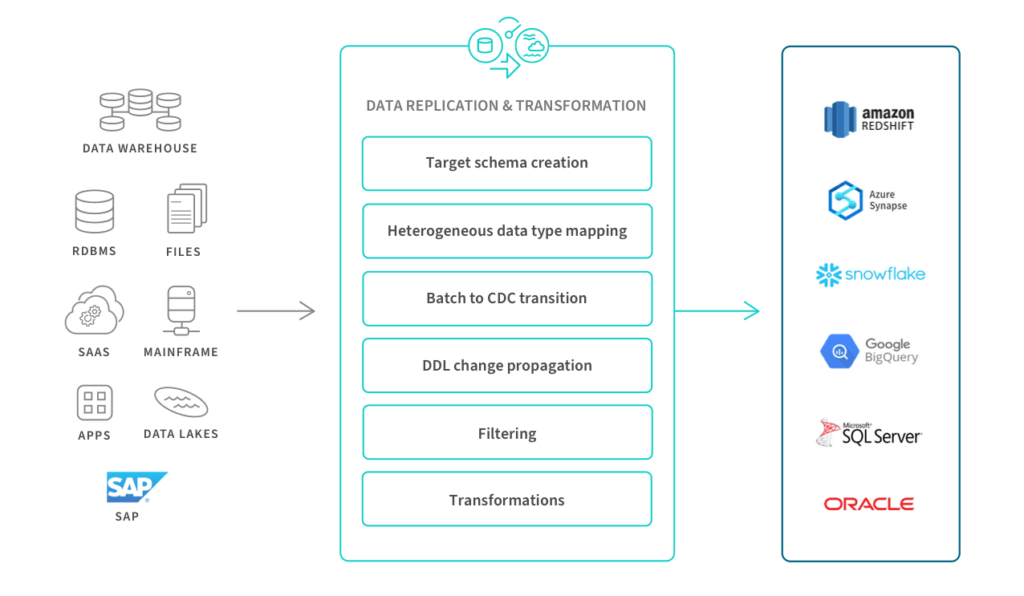
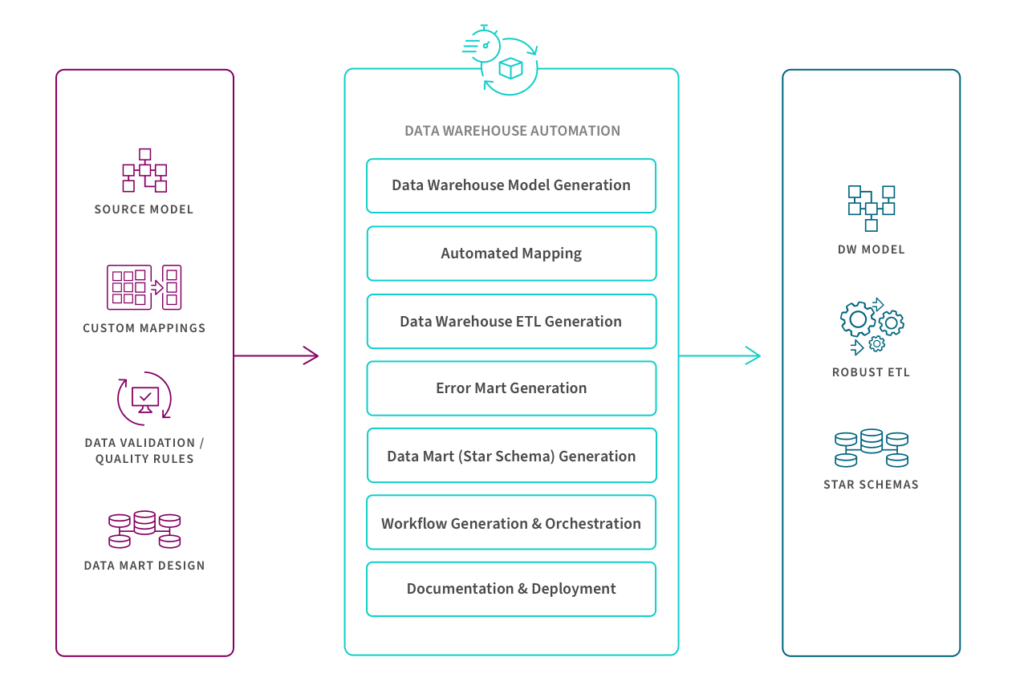
Caso d’Uso #3: Data Warehouse Automation
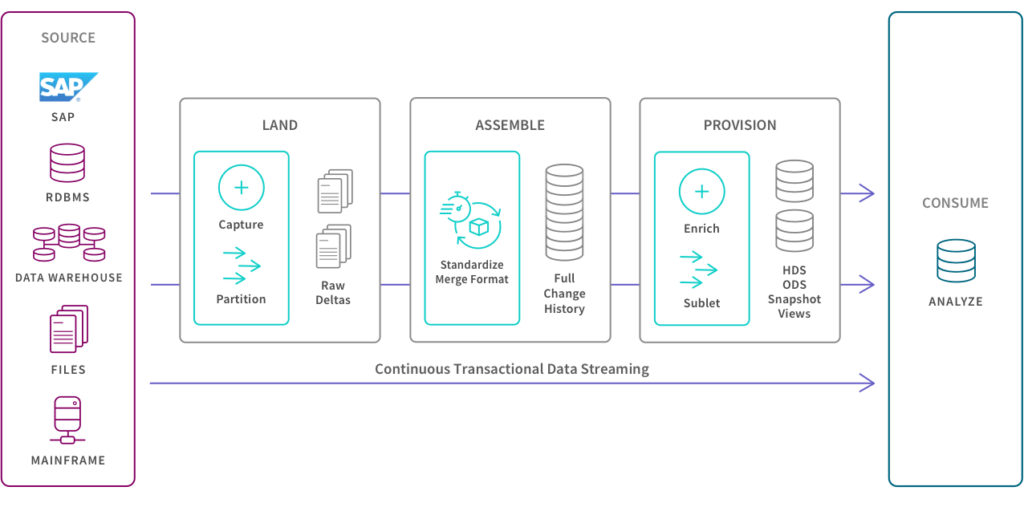
Il processo di automazione del Data Warehouse accelera la disponibilità di dati pronti per l’analisi automatizzando il ciclo di vita del Data Warehouse, dalla modellazione dei dati e ingestione in tempo reale fino ai Data Mart e alla governance. Questo diagramma mostra i passaggi chiave per la creazione e l’operatività del Data Warehouse tramite un processo automatizzato e di raffinamento continuo.
Caso d’Uso #4: Big Data Integration
Lo spostamento e la gestione dell’enorme volume, varietà e velocità dei dati strutturati, semi-strutturati e non strutturati associati ai Big Data richiedono strumenti e tecniche avanzate. L’obiettivo è fornire ai tuoi strumenti di analisi dei big data e ad altre applicazioni una visione completa e aggiornata della tua attività. Ciò significa che il tuo sistema di integrazione deve disporre di pipeline intelligenti in grado di spostare, consolidare e trasformare automaticamente i big data provenienti da più fonti, mantenendo la tracciabilità (lineage). Deve inoltre garantire elevata scalabilità, prestazioni, profilazione e funzionalità di qualità dei dati per gestire dati in tempo reale e in streaming continuo.
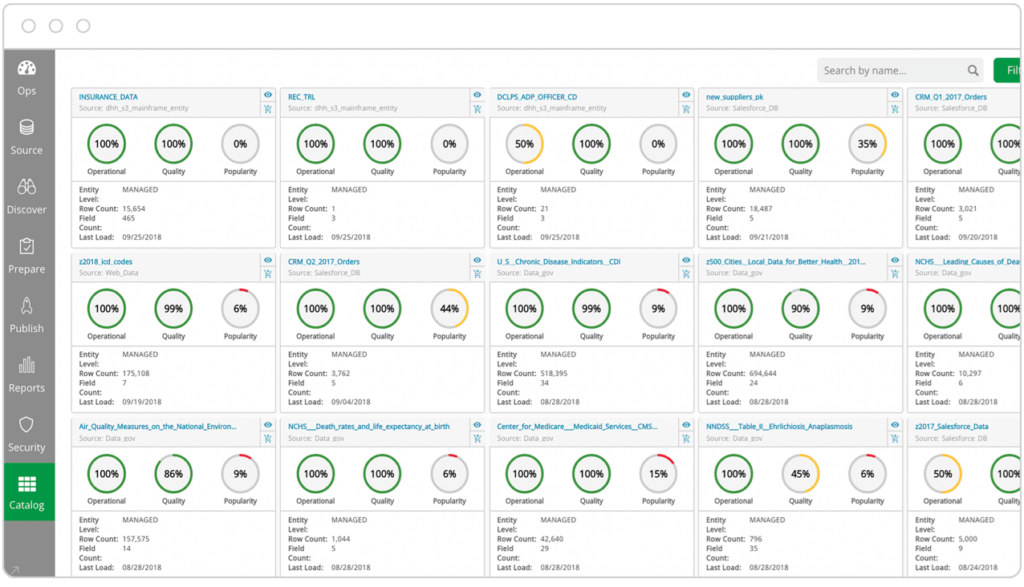
Data Governance
La Data Governance si riferisce al processo di definizione di standard interni per i dati e di politiche di utilizzo, utilizzando tecnologie e processi per mantenere e gestire la sicurezza, l’integrità, la tracciabilità (lineage), l’usabilità e la disponibilità dei dati. Un catalogo dati governato profila e documenta ogni fonte di dati e definisce chi, all’interno di un’organizzazione, può eseguire determinate azioni su specifici dati. Queste politiche e standard consentono agli utenti di trovare, preparare, utilizzare e condividere più facilmente set di dati affidabili in modo autonomo, senza dipendere dall’IT.
Vantaggi Principali della Data Integration
In definitiva, la Data Integration elimina i silos di dati e consente di analizzare e agire su una singola fonte affidabile di dati governati. Le organizzazioni sono sommerse da set di dati grandi e complessi provenienti da molte fonti diverse e scollegate: piattaforme pubblicitarie, sistemi CRM, automazione del marketing, analisi web, sistemi finanziari, dati dei partner, fino alle fonti in tempo reale e all’IoT. E, a meno che analisti o ingegneri dei dati non dedichino innumerevoli ore alla preparazione dei dati per ciascun report, tutte queste informazioni non possono essere collegate insieme per fornire una visione completa del business.
L’integrazione fornisce una singola fonte affidabile di dati governati, completi, accurati e aggiornati. Questo consente ad analisti, data scientist e professionisti aziendali di utilizzare strumenti di BI e analisi per esplorare e analizzare l’intero set di dati, identificare modelli e ottenere insight azionabili che migliorano le prestazioni.
Ecco tre vantaggi chiave:
- Maggiore accuratezza e affidabilità
Tu e gli altri stakeholder potrete smettere di chiedervi quale KPI di quale strumento sia corretto o se alcuni dati siano stati inclusi. Saranno inoltre ridotti gli errori e le rilavorazioni. L’integrazione fornisce una singola fonte affidabile di dati governati e accurati su cui fare affidamento: “una sola versione della verità”. - Decisioni collaborative e basate sui dati
Gli utenti di tutta l’organizzazione saranno molto più propensi a impegnarsi nell’analisi una volta che i dati grezzi e i silos saranno trasformati in informazioni accessibili e pronte per l’analisi. Saranno anche più inclini a collaborare tra i reparti, poiché i dati provenienti da ogni parte dell’azienda sono combinati e permettono di vedere chiaramente come le attività di ciascuno influenzano le altre. - Maggiore efficienza
I team di analisi, sviluppo e IT possono concentrarsi su iniziative più strategiche, non dovendo più dedicare tempo alla raccolta manuale e alla preparazione dei dati o alla creazione di connessioni ad hoc e report personalizzati.
Application Integration vs. Data Integration
L’API e la Data Integration sono strettamente correlate, ma presentano alcune differenze chiave. Esaminiamo le definizioni e i processi principali:
- Application Integration (API): Consente ad applicazioni separate di lavorare insieme spostando e sincronizzando i dati tra di esse. Il caso d’uso più tipico è il supporto delle esigenze operative, come garantire che il tuo sistema HR abbia gli stessi dati del sistema finanziario. Pertanto, l’integrazione delle applicazioni deve assicurare la coerenza tra i set di dati. Inoltre, queste applicazioni hanno solitamente API uniche per inviare e ricevere dati, quindi gli strumenti di automazione delle applicazioni SaaS possono aiutarti a creare e mantenere integrazioni API native in modo efficiente e su larga scala.
- La Data Integration, come descritto in precedenza, sposta i dati da molteplici fonti in un’unica posizione centralizzata. Il caso d’uso più tipico è il supporto agli strumenti di Business Intelligence (BI) e analisi. Gli strumenti e i processi moderni di Data Integration sono in grado di gestire dati operativi e in tempo reale, ma storicamente l’integrazione si è concentrata sul trasferimento di dati statici e relazionali tra i Data Warehouse.
Qlik Talend® Cloud: La Soluzione Completa per la Data Integration
Qlik Talend® Cloud è la risposta ideale alle esigenze moderne di Data Integration viste in questa guida.
Grazie alla sua architettura avanzata, questa piattaforma permette di implementare tutti i principali approcci di integrazione: ETL ed ELT per trasformare e caricare i dati in maniera efficiente, streaming per la gestione dei dati in tempo reale, e API per sincronizzare applicazioni aziendali in modo fluido e scalabile. La virtualizzazione dei dati, inoltre, consente di combinare fonti diverse, offrendo una vista unificata dei dati su richiesta.
Con Qlik Talend® Cloud, puoi automatizzare l’intero ciclo di vita del data warehouse, accelerando la creazione e la governance dei dati pronti per l’analisi. La piattaforma è in grado di gestire volumi enormi di big data, consolidando e trasformando dati strutturati e non strutturati provenienti da più sorgenti. Grazie al Change Data Capture (CDC), Qlik Talend® Cloud garantisce l’aggiornamento continuo dei dati, supportando sia il caricamento incrementale che flussi di dati in tempo reale.
Con strumenti integrati di data quality e governance, Qlik Talend Cloud assicura che i dati siano sempre accurati, affidabili e accessibili, eliminando i silos e consentendo alle aziende di ottenere insight strategici in tempi rapidi. Che si tratti di ingestion, replica, automazione o integrazione dei big data, questa soluzione centralizza e semplifica la gestione dei dati, offrendo un’unica piattaforma per soddisfare tutte le esigenze aziendali.
Semplifica, automatizza e valorizza i tuoi dati con Qlik Talend® Cloud.
Affidati alla Nostra Expertise in Data Integration
In SELDA Informatica, abbiamo maturato una solida esperienza nella Data Integration, supportando aziende di ogni dimensione nella trasformazione e valorizzazione dei dati. La nostra competenza spazia dalla creazione di pipeline avanzate alla gestione di data warehouse, integrazioni API e progetti di big data analytics, utilizzando soluzioni leader come Qlik Talend® Cloud.
Siamo qui per aiutarti a eliminare i silos, centralizzare i tuoi dati e implementare processi automatizzati e scalabili che garantiscano accuratezza, efficienza e collaborazione tra i reparti.
Contattaci oggi stesso per scoprire come la nostra expertise può ottimizzare i tuoi processi di Data Integration, offrendoti una visione chiara e affidabile del tuo business.
👉 Parla con i nostri esperti e inizia subito a trasformare i tuoi dati in valore!
