
Le trasformazioni e manipolazioni dei dati sono solitamente dominio di esperti in SQL, Python o altri linguaggi di programmazione. Poiché in passato le trasformazioni erano codificate manualmente, il loro sviluppo richiedeva molte risorse. Inoltre, una volta implementate, le trasformazioni dovevano essere aggiornate e mantenute poiché i requisiti aziendali cambiavano e nuove fonti di dati venivano aggiunte o modificate.
Uno degli obiettivi delle soluzioni di Data Integration è assistere gli utenti nella gestione e trasformazione dei dati eliminando le barriere a questo processo.
E se potessi automatizzare e costruire i tuoi flussi di trasformazione senza alcuna codifica manuale utilizzando un’interfaccia visiva?
I flussi di trasformazione di Qlik Talend® Cloud aiutano a portare capacità avanzate di trasformazione agli utenti di ogni livello. Il flusso di trasformazione si basa su un’interfaccia grafica senza codice che guida l’utente nella trasformazione dei dati.
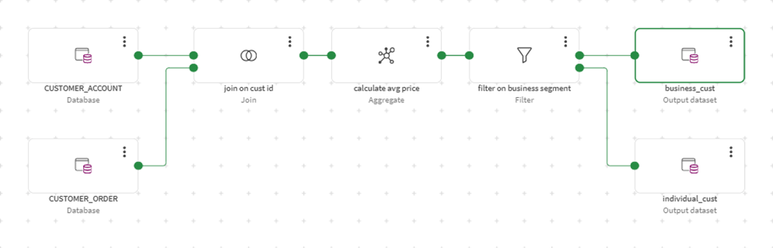
L’interfaccia richiede solo la conoscenza dei dati e del risultato di trasformazione desiderato. Mentre l’utente costruisce i flussi di trasformazione, il sistema genera il codice SQL ottimizzato per la piattaforma di destinazione e visualizza i risultati per la verifica durante il processo.
La chiave dell’approccio “senza codice” (no-code) dei flussi di trasformazione è il concetto di processori configurabili.
Questi processori funzionano come blocchi di costruzione che prendono i dati grezzi da una tabella sorgente o da un processore precedente come input ed eseguono un’operazione per trasformare e produrre dati come output.
Un’ampia gamma di processori è disponibile all’interno di Qlik Talend® Cloud, tra cui processori per aggregare, pulire, filtrare, unire e molto altro (vedi sotto). Attualmente, tutti i processori vengono eseguiti utilizzando un paradigma ELT push-down. Ciò significa che i processori generano istruzioni SQL compatibili con la piattaforma di database o Data Warehouse di destinazione del progetto, quindi eseguono queste istruzioni utilizzando le risorse di calcolo e i dati presenti sulla piattaforma Cloud di destinazione – come Snowflake, Databricks o altri.
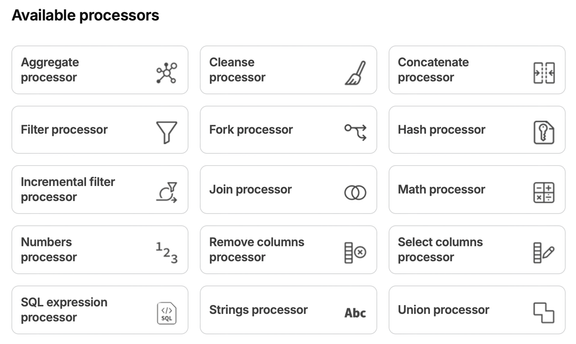
Iniziare con i Flussi di Trasformazione
Se stai già utilizzando Qlik Talend® Cloud Data Pipelines, puoi creare flussi di trasformazione all’interno degli oggetti di trasformazione dei progetti di Data Integration.
Esaminiamo alcuni esempi di flussi di trasformazione nel contesto dei dati dei clienti. Prima filtreremo e divideremo i dati dei clienti da SAP per area geografica. Successivamente, li combineremo con dati provenienti da altri sistemi per ottenere un elenco consolidato dei clienti.
Esempio di Filtraggio e Divisione
I passaggi per filtrare e dividere i dati dei clienti per posizione/geografia sono i seguenti:
- Selezionare il master dei clienti (KNA1) e il flusso di trasformazione in un’attività di trasformazione esistente.
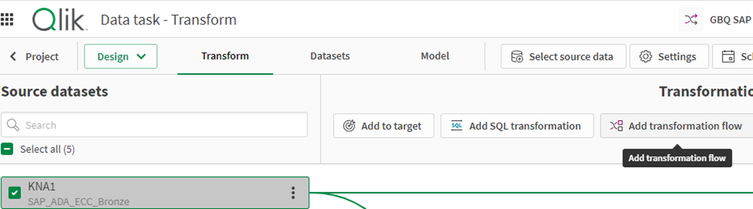
- Compilare i dettagli: il nome della trasformazione, il set di dati di output predefinito e, facoltativamente, le impostazioni di materializzazione. La materializzazione memorizzerà i risultati del flusso di trasformazione come tabella fisica nel database di destinazione. Se non materializzato, i risultati saranno memorizzati come una vista renderizzata su richiesta da altri oggetti della pipeline di dati. Affinché l’attività di trasformazione possa gestire i carichi incrementali utilizzando il processore filtro incrementale, la materializzazione deve essere impostata su ON.
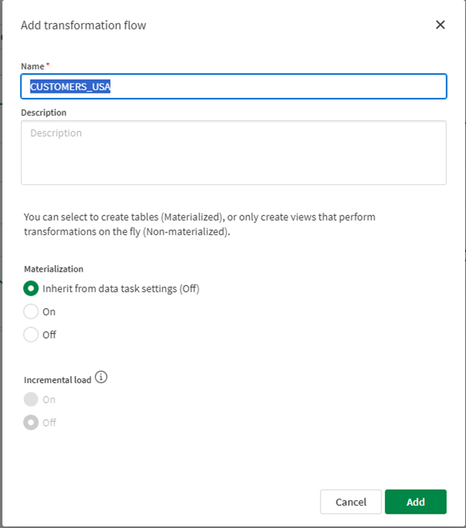
- La nostra trasformazione predefinita appare come segue:
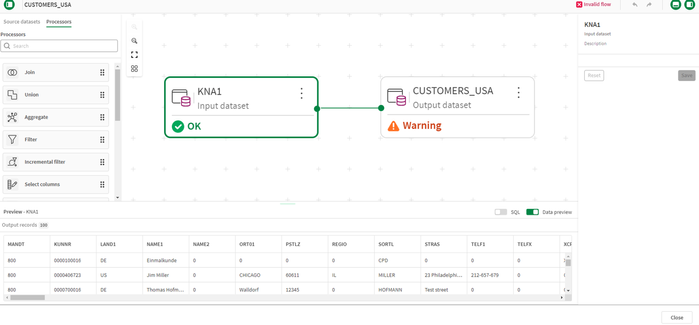
Quando crei un flusso di trasformazione, l’interfaccia utente di Qlik Talend® Cloud mostrerà per impostazione predefinita il set di dati di input selezionato nel passaggio precedente e il set di dati di output. Il set di dati di output avrà il nome della trasformazione, ma il nome può essere modificato dallo sviluppatore del flusso di trasformazione.
Suggerimento rapido: Per iniziare a costruire un flusso di trasformazione, seleziona il set di dati di input e attiva l’anteprima dei dati. Questo mostrerà i campi e i dati disponibili da utilizzare nel flusso di trasformazione. Nota che il campo LAND1 contiene il paese del cliente.
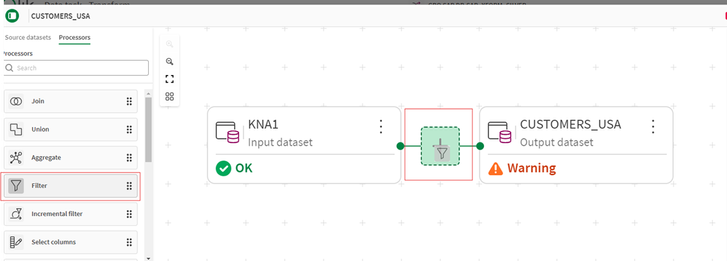
- Selezioniamo quindi il processore Filtro e lo inseriamo tra l’input e l’output.
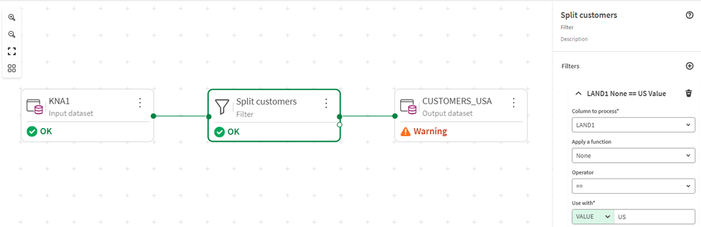
- Configuriamo poi il filtro per limitare i dati ai clienti statunitensi e facciamo clic su Salva. Con il filtro applicato per suddividere i clienti, l’anteprima dei dati nella parte inferiore dello schermo si aggiorna mostrando solo le righe corrispondenti al filtro.

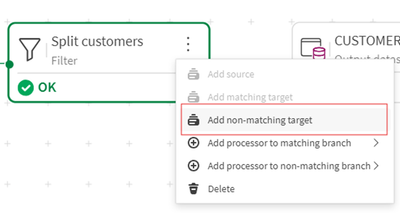
- Successivamente, configuriamo un output per i record non corrispondenti. L’output non corrispondente conterrà tutti i clienti non statunitensi.
- Infine, definiamo una chiave per entrambi i set di dati. Le chiavi possono essere definite nei metadati di ciascun oggetto facendo clic su Modifica e selezionando le colonne. Puoi verificare che il set di dati rispetti le chiavi definite facendo clic sul pulsante Convalida dati.
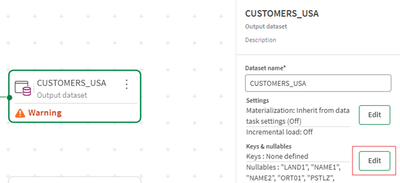
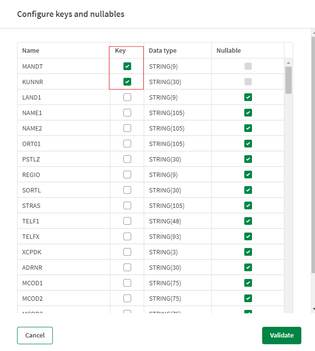
- Non dimenticare di fare clic su Salva per uscire e applicare le modifiche.
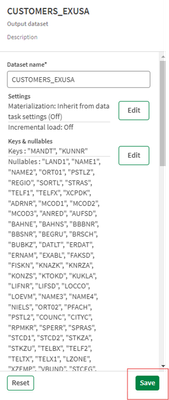
- Il flusso di trasformazione completato appare come segue:
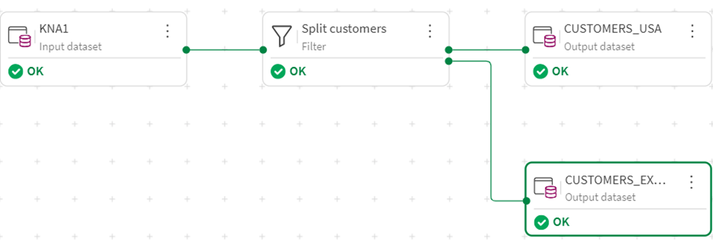
Combinare Dati da Più Fonti
Costruendo sulla trasformazione precedente, ora combineremo i dati filtrati dei clienti SAP con un diverso set di clienti proveniente da un sistema basato su Oracle.
- Similmente al passaggio precedente, seleziona i due set di dati da combinare in un flusso di trasformazione. Con Qlik Talend® Cloud, è facile aggiungere e combinare nuovi set di dati. Puoi caricare automaticamente e continuamente i dati senza pianificare job o scrivere script, semplicemente trascinando e rilasciando le fonti.
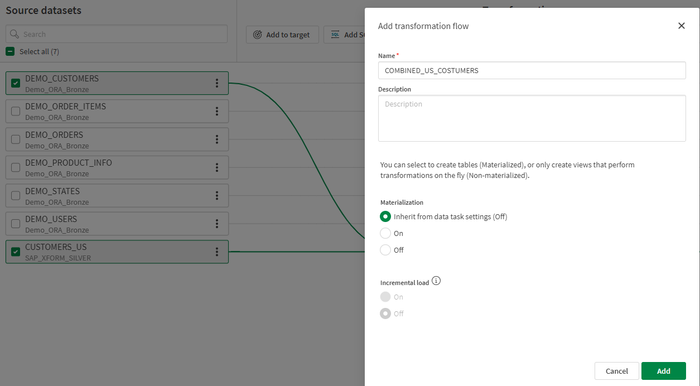
- Il canvas ora mostra i due set di dati di input e il set di output.

- Possiamo quindi ispezionare entrambi i set di dati facendo clic su di essi e controllando il pannello di anteprima.


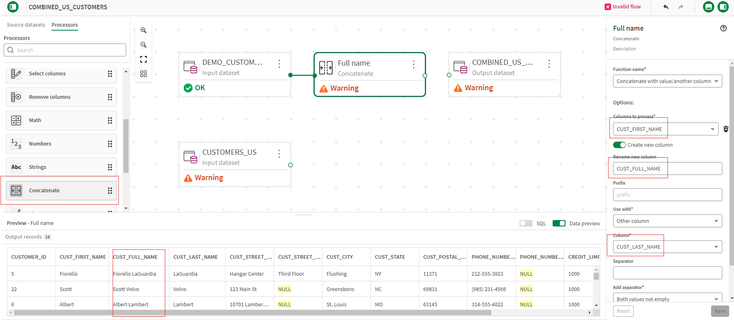
- Notiamo che le informazioni di contatto dei clienti sembrano facilmente combinabili; indirizzi e numeri di telefono hanno un formato simile. I nomi dei clienti sono diversi: la fonte Oracle ha campi separati per nome e cognome, mentre SAP ha un campo unico per il nome. Per questo esempio, standardizzeremo su un campo unico utilizzando un processore Concatenate sulla fonte Oracle.
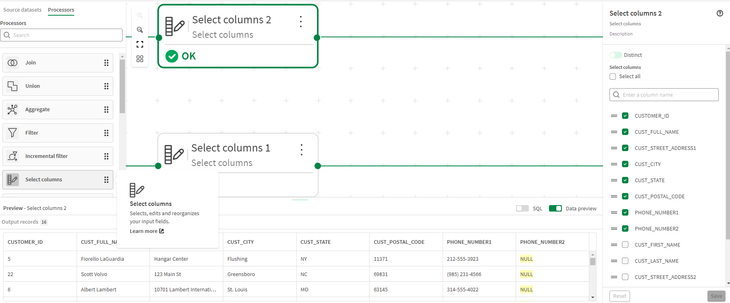
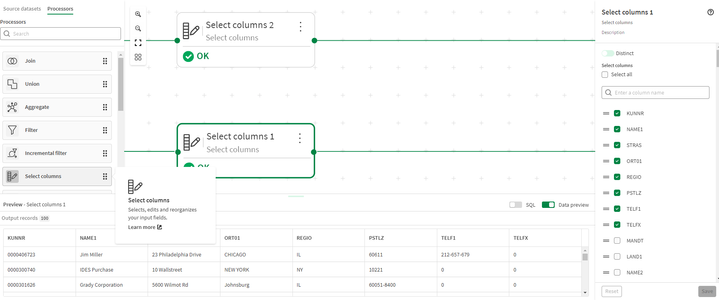
- Utilizziamo quindi un processore Select columns per selezionare e ordinare le colonne di entrambi i set di dati in preparazione per l’unione.
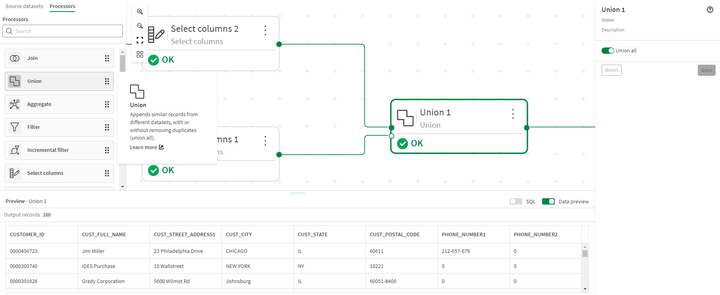
- Utilizziamo poi il processore Union per combinare i set di dati.
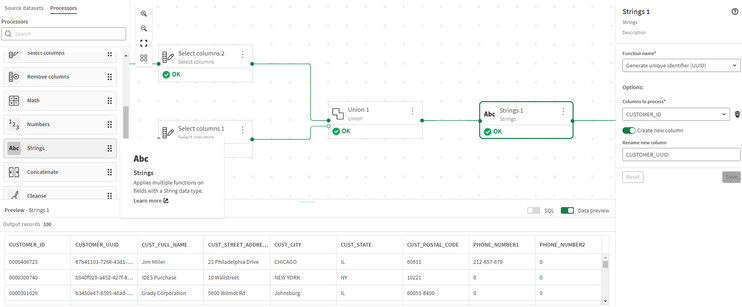
- Aggiungiamo infine una colonna UUID al set di dati combinato da utilizzare come chiave.
- Configuriamo l’output con questa chiave.
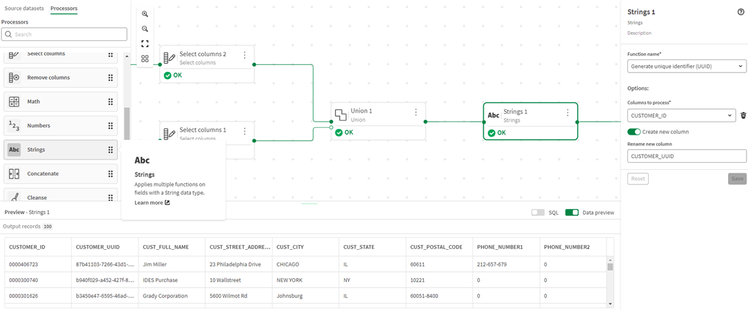
- Il nostro flusso di trasformazione è ora completo.


I flussi di trasformazione in Qlik Talend® Cloud permettono agli utenti senza competenze avanzate di programmazione (SQL, Python, ecc.) di trasformare facilmente ed efficacemente i loro dati per l’analisi. L’interfaccia grafica semplifica l’implementazione astratta dalla sintassi del linguaggio, presentando i processori come elementi configurabili.
Funzionalità complesse, come caricare dati incrementali o applicare filtri, vengono gestite automaticamente dal prodotto. Basta abilitare l’opzione di carico incrementale e includere il processore Incremental filter. Tuttavia, il carico incrementale è disponibile solo se il set di dati è stato materializzato.
Rendere le trasformazioni dei dati più accessibili migliora la comunicazione dei requisiti, riducendo i tempi di costruzione delle pipeline e facilitando gli aggiornamenti quando i requisiti evolvono.
I flussi di trasformazione sono al centro delle capacità di trasformazione di Qlik Talend® Cloud e sono disponibili per l’uso immediato.
Ottimizza i tuoi Dati con SELDA e Qlik Talend® Cloud
Affidati alla nostra esperienza pluriennale nell’integrazione e trasformazione dei dati con strumenti avanzati come Qlik Talend® Cloud. SELDA Informatica offre soluzioni personalizzate, consulenza e supporto per aiutarti a ottimizzare le tue pipeline di dati e trasformare le informazioni in valore strategico.
Contattaci oggi stesso per scoprire come possiamo semplificare e potenziare la gestione dei tuoi dati.
