
Ti sei mai trovato bloccato con un mucchio di dati disordinati che sembra più un labirinto che un percorso verso analisi pulite? Non sei solo. Oggi, ci immergiamo nel mondo della pulizia dei dati in Qlik Sense per aiutarti a scoprire il potenziale analitico nascosto dietro i tuoi dati.
L’importanza della pulizia dei dati
Immagina di preparare una torta. Ti affideresti a stime approssimative per le quantità degli ingredienti? Probabilmente no, a meno che tu non voglia creare un disastro. Così come una misura imprecisa di farina può rovinare l’intera ricetta, un piccolo errore nei dati può compromettere tutta l’analisi. Ecco perché, prima di tuffarti nella parte divertente – l’analisi dei dati – devi assicurarti che il tuo ingrediente chiave (i dati) sia il più pulito e preciso possibile.
Perché la pulizia dei dati è più che una semplice seccatura
Non si tratta solo di mettere ordine; è una questione di controllo della qualità. Saltare dei passaggi o trascurare degli errori può portare a risultati inaccurati che potrebbero fuorviare le tue decisioni aziendali.
Accuratezza dei dati
L’accuratezza delle tue analisi dipende fortemente dalla qualità dei tuoi dati. La pulizia dei dati aiuta a eliminare errori e incongruenze, garantendo che le tue intuizioni siano affidabili e applicabili. Strumenti come le tabelle di mappatura o funzioni come SubField possono essere preziosi in questa fase.
Consistenza dei dati
Formati di dati incongruenti o convenzioni di denominazione possono essere un vero ostacolo. Anche qui la funzione SubField e le tabelle di mappatura in Qlik Sense possono aiutarti a standardizzare i dati per report e visualizzazioni coerenti.
Integrazione dei dati
Quando integri dati da varie fonti, l’allineamento è cruciale. Qlik Sense fornisce numerose funzioni che aiutano ad allineare questi set di dati disparati in una forma coesa e unificata.
Miglioramento della visualizzazione e delle prestazioni
Dati puliti non solo rendono le tue visualizzazioni più significative; migliorano anche le prestazioni delle tue applicazioni Qlik. Aspettati un recupero dati più veloce e un’analisi più efficiente quando i tuoi dati sono in buona forma.
Tecniche di pulizia dei dati in Qlik Sense
Rimozione dei duplicati
I record duplicati possono distorcere la tua analisi e i report. Qlik offre funzioni integrate come Keep quando carichi tabelle o la parola chiave DISTINCT nel tuo script per caricare solo le righe uniche.
Valori mancanti
Puoi affrontare i valori mancanti rimuovendo i record o riempiendo le lacune in base a criteri specifici. Funzioni come IsNull, IsNullCount e NullAsValue sono utili.
Formattazione dei dati
Utilizzando le numerose funzioni di stringa disponibili in Qlik Sense, puoi standardizzare i valori dei dati in un formato coerente. Ad esempio, le funzioni Upper, Lower, Date e Num possono essere utilizzate per unificare testo o date.
Manipolazione dei dati
A volte i dati che importi in Qlik Sense non si adattano esattamente alle tue esigenze. Qlik offre modi per rimodellare i tuoi dati di conseguenza.
Per esempio, valori di campo inconsistenti possono verificarsi spesso quando si estraggono dati da più tabelle e questa incongruenza può interrompere le connessioni tra i set di dati. Una soluzione efficiente a questo è l’uso delle tabelle di mappatura.
Tabelle di mappatura in Qlik Sense
Questi tipi di tabelle si comportano diversamente rispetto ad altre tabelle in quanto sono memorizzate in un’area separata della memoria e sono strettamente utilizzate come tabelle di mappatura quando lo script è eseguito, dopodiché vengono automaticamente eliminate.
Vediamo come è possibile crearle e le diverse istruzioni e funzioni che possono essere utilizzate:
Prefisso MAPPING
Viene utilizzato per creare una tabella di mappatura. Ad esempio:
CountryMap:
MAPPING LOAD * INLINE [
Country, NewCountry
U.S.A., US
U.S., US
United States, US
United States of America, US
];
Tieni presente che una tabella di mappatura deve avere due colonne, la prima contenente i valori di confronto e la seconda contenente i valori di mappatura desiderati.
ApplyMap()
La funzione ApplyMap è usata per sostituire i dati in un campo basato su una tabella di mappatura precedentemente creata.
CountryMap:
MAPPING LOAD * INLINE [
Country, NewCountry
U.S.A., US
U.S., US
United States, US
United States of America, US
];
Data:
LOAD
ID,
Name,
ApplyMap(‘CountryMap’, Country) as Country,
Code
FROM [lib://DataFiles/Data.xlsx]
(ooxml, embedded labels, table is Sheet1);
Il primo parametro in ApplyMap è il nome della tabella di mappatura tra virgolette. Il secondo parametro è il campo contenente i dati che devono essere mappati.
Puoi aggiungere un terzo parametro alla funzione ApplyMap che funge da impostazione predefinita per gestire i casi in cui il valore non corrisponde ad uno nella tabella di mappatura.
Ad esempio:
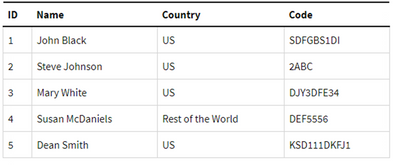
ApplyMap(‘CountryMap’, Country, ‘Rest of the World’) as Country
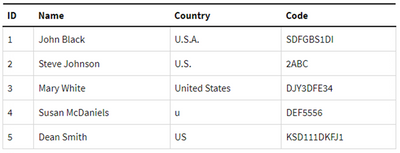
Dopo la mappatura:
MapSubstring()
La funzione MapSubstring è usata per mappare parti di un campo e può essere un’alternativa alle funzioni Replace() o PurgeChar().
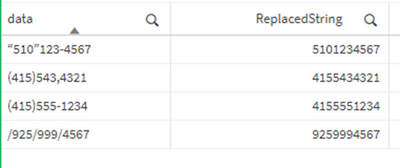
Per esempio, puliamo questi valori di numeri di telefono da caratteri indesiderati:
ReplaceMap:
MAPPING LOAD * INLINE [
char, replace
“)”, “”
“(“, “”
“\””, “”
“/”, “”
“-“, “”
] (delimiter is ‘,’);
TestData:
LOAD
DataField as data,
MapSubString(‘ReplaceMap’, DataField) as ReplacedString
INLINE [
DataField
“(415)555-1234”,
“(415)543,4321”,
““510”123-4567”,
“/925/999/4567”
] (delimiter is ‘,’);
Dopo la pulizia:
MAP… USING
L’istruzione Map… Using funziona in modo diverso rispetto alla funzione ApplyMap() in quanto ApplyMap esegue la mappatura ogni volta che viene incontrato il nome del campo, mentre Map… Using esegue la mappatura quando i valori vengono archiviati sotto il nome del campo nella tabella interna.
Ad esempio, nel seguente script di caricamento, la mappatura verrà applicata al campo Country in Data1, tuttavia non verrà applicata al campo Country2 nella tabella Data2.
Questo perché l’istruzione Map… USING viene applicata solo al campo denominato Country. Ma in Data2, il campo viene archiviato come Country2 nella tabella interna.
Map Country Using CountryMap;
Data1:
LOAD
ID,
Name,
Country
FROM [lib://DataFiles/Data.xlsx]
(ooxml, embedded labels, table is Sheet1);
Data2:
LOAD
ID,
Country as Country2
FROM [lib://DataFiles/Data.xlsx]
(ooxml, embedded labels, table is Sheet1);
UNMAP;
Funzioni utili per la pulizia dei dati in Qlik Sense
SubField()
Utilizzata per estrarre sottostringhe da un campo stringa costituito da due o più parti separate da un delimitatore.
I parametri accettati sono Text (stringa originale), un delimitatore (carattere all’interno del testo di input che divide la stringa in parti) e field_no che può essere 1 per restituire la prima sottostringa (a sinistra) o 2 per restituire la seconda sottostringa (a destra)
SubField(text, delimiter, field_no)
Ad esempio:
UserData:
LOAD * INLINE [
UserID, FullName
1, “John,Doe”
2, “Jane,Doe”
3, “Alice,Wonderland”
4, “Bob,Builder”
];
CleanedData:
LOAD
UserID,
SubField(FullName, ‘,’, 1) as FirstName,
SubField(FullName, ‘,’, 2) as LastName
RESIDENT UserData;
Drop Table UserData;
Len()
Restituisce la lunghezza della stringa di input.
Left()
Restituisce una stringa dei primi (left) caratteri della stringa di input, dove il numero di caratteri è determinato dal secondo parametro.
Left(text, count)
Right()
Simile a left, restituisce una stringa degli ultimi (più a destra) caratteri della stringa di input. Il secondo parametro determina il numero di caratteri da restituire.
Index()
La funzione index cerca una stringa e restituisce la posizione di partenza della n-esima occorrenza di una sottostringa fornita.
Ad esempio:
Index(‘qwerty’, ‘ty’) restituirà 5
Index(‘qwertywy’, ‘w’, 2) restituirà la seconda occorrenza di ‘w’, ovvero: 7
Esempio 1
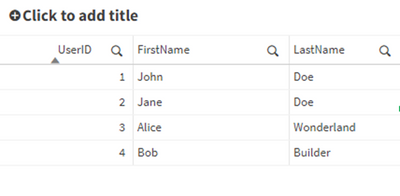
Utilizzare una combinazione delle funzioni di cui sopra per ripulire un campo. Prendiamo un campo più complesso e proviamo ad estrarre nome e cognome.
UserData:
LOAD * INLINE [
UserID, Object
1, “37642UI101John.Doe”
2, “98322UI101Jane.Doe”
3, “45432UI101Alice.Wonderland”
4, “32642UI101Bob.Builder”
];
CleanedData:
LOAD
UserID,
SubField(Right(Object, Len(Object) – Index(Object, ‘UI101’) – 4), ‘.’, 1) as FirstName,
SubField(Right(Object, Len(Object) – Index(Object, ‘UI101’) – 4), ‘.’, 2) as LastName
RESIDENT UserData;
Drop Table UserData;
Dopo la pulizia:
Esempio 2
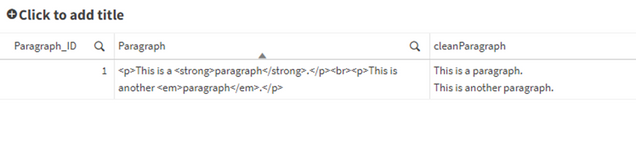
Pulizia dell’HTML in un campo.
Paragraphs:
LOAD * INLINE [
Paragraph_ID, Paragraph
1, “
This is a paragraph.
This is another paragraph.”
];
// Loop through each paragrpah in the Paragraphs table
For vRow = 1 to NoOfRows(‘Paragraphs’)
Let vID = Peek(‘Paragraph_ID’, vRow-1, ‘Paragraphs’); // Get the ID of the next record to parse
Let vtext = Peek(‘Paragraph’, vRow-1, ‘Paragraphs’); // Get the original paragraph of the next record
// Loop through each paragraph in place
Do While len(TextBetween(vtext, ‘<‘, ‘>’)) > 0
vtext = Replace(vtext, ‘
‘, chr(10)); // Replace line breaks with carriage returns – improves legibility
vtext = Replace(vtext, ‘<‘ & TextBetween(vtext, ‘<‘, ‘>’) & ‘>’, ”); // Find groups with <> and replace them with ”
Loop;
// Store the cleaned paragraphs into a temporary table
Temp:
Load
$(vID) as Paragraph_ID,
‘$(vtext)’ as cleanParagraph
AutoGenerate 1;
Next vRow;
// Join the cleaned paragraphs back into the original Paragraphs table
Left Join (Paragraphs)
Load *
Resident Temp;
// Drop the temporary table
Drop Table Temp;
Dopo la pulizia:
Speriamo che questo tutorial ti sia stato utile!
Buona pulizia dei dati e felice analisi!
